


지난 AWSKRUG 플랫폼엔지니어링 밋업에서 소개받은 KEDA에 대해 설명해볼까 합니다. 쿠버네티스에는 Auto Scaling을 위한 Horizontal Pod Autoscaling이 있습니다. 하지만 이 기본적인 HPA(Horizontal Pod Autoscaler)는 CPU나 메모리 사용량만을 기준으로 확장 정책을 설정할 수 있습니다. 이러한 한계를 극복하기 위해 등장한 것이 바로 KEDA(Kubernetes Event-driven Autoscaling)입니다.
KEDA란?
KEDA는 Kubernetes에 이벤트 기반 확장 기능을 추가하는 오픈소스 프로젝트입니다. KEDA는 애플리케이션 워크로드를 이벤트 매개 변수에 따라 동적으로 확장하거나 축소할 수 있도록 지원하며, 클라우드 네이티브 애플리케이션을 더 효율적으로 실행할 수 있는 환경을 제공합니다.
KEDA의 주요 기능
- 이벤트 기반 확장
KEDA는 애플리케이션의 부하를 결정하는 이벤트(메시지 큐 길이, 데이터베이스 요청 수 등)를 기반으로 확장을 관리합니다. 이를 통해 사용자가 직접 설정한 메트릭에 따라 확장 정책을 정의할 수 있습니다. - 리소스 0으로 줄이기 가능
애플리케이션에 이벤트가 없을 때는 리소스를 완전히 줄여 0으로 만들 수 있습니다. 이를 통해 불필요한 리소스 사용을 줄이고 비용을 절감할 수 있습니다. - 다양한 Scaler 지원
KEDA는 다양한 외부 시스템과 통합할 수 있는 Scaler를 제공합니다.
- Azure Queue
- Apache Kafka
- RabbitMQ
- Prometheus
- AWS SQS
- Redis 등
- 기존 HPA와의 통합
KEDA는 Kubernetes의 HPA를 확장하여 동작합니다. 따라서 기존 Kubernetes 사용자는 별도의 복잡한 설정 없이 HPA와 함께 KEDA를 사용할 수 있습니다.
KEDA 아키텍처
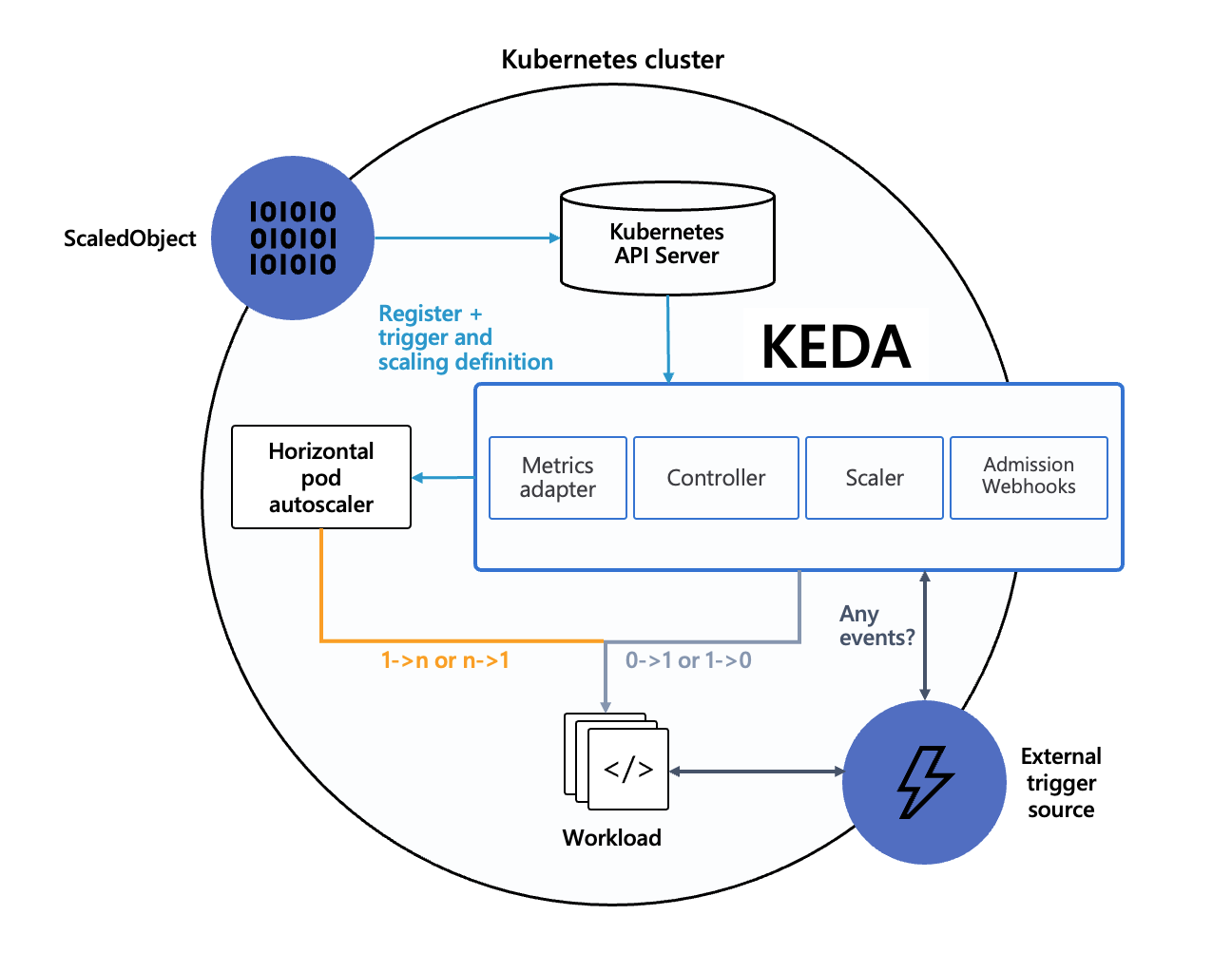
KEDA의 구성은 크게 두 가지 주요 컴포넌트로 나뉩니다:
- KEDA Operator
- Kubernetes 클러스터에 배포되는 컨트롤러.
- ScaledObject 리소스를 관리하고 HPA를 생성 또는 업데이트합니다.
- Metrics Server
- ScaledObject에 정의된 메트릭 값을 수집하고 HPA에 전달하여 확장 정책을 실행합니다.
KEDA의 장점과 한계
장점
- 유연한 확장 정책: 다양한 이벤트 소스를 지원하여 세밀한 확장 정책 정의 가능.
- 비용 효율성: 사용량이 없는 경우 0까지 축소 가능.
- 사용 편의성: Kubernetes 환경에 간단히 통합 가능.
한계
- 복잡성 증가: 다양한 외부 시스템과의 통합 설정이 복잡할 수 있음.
- 메트릭 의존성: 외부 메트릭 수집 시스템이 비정상 동작할 경우 확장 정책이 실패할 가능성.
KEDA 설치 및 설정
KEDA 설치
Helm Chart를 이용하여 간단히 KEDA를 설치할 수 있습니다.
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace
커스텀 리소스 적용가능 여부 확인하기
KEDA에 의해 스케일링이 가능한 커스텀 리소스는 반드시 subresources로 scale이 정의되어 있어야 합니다.
subresources에 대한 정의는 각 CRD(Custom Resource Definition)에 명시되어 있으며, 일반적으로 CRD의 버전(spec.versions) 정의 아래에 존재합니다. 이 글에서는 서브리소스에 대한 설명은 생략하도록 합니다.
subresource에 scale이 적용되어있는 CRD의 예입니다.
subresources:
scale:
labelSelectorPath: .status.selector
specReplicasPath: .spec.replicas
statusReplicasPath: .status.HPAReplicas
status: {}
확인 방법
적용하려는 커스텀 리소스가 KEDA에서 스케일링 가능한지 확인하려면, 다음과 같이 yq를 활용해 확인할 수 있습니다. 이렇게 하면 CRD가 정의되어있는 파일에서 어떤 리소스가 사용가능한지 확인할 수 있습니다.
yq -r 'select(.spec.versions[].subresources.scale != null) | .spec.names.kind' <CRD파일>
스케일링 시나리오
스케일링을 멈추려면
스케일링 대상의 annotation에 다음과 같이 적용하면 됩니다.
# 현재 replicas의 수에서 멈추기
metadata:
annotations:
autoscaling.keda.sh/paused: "true"
---
# 특정 수에서 멈추기
metadata:
annotations:
autoscaling.keda.sh/paused-replicas: "0"
일정 시간마다 수 조절하기
반대로 설정하면 이 설정을 통해서 업무시간 외에는 파드의 수를 0으로 만들어둘 수도 있습니다.
triggers:
- type: cron
metadata:
# Required
timezone: Asia/Seoul
start: 42 * * * * # 시작 시간
end: 43 * * * * # 종료 시간
desiredReplicas: "5"
'K8S > ecosystem' 카테고리의 다른 글
| Kubernetes Controller에서 Owns와 Watches의 차이점 (0) | 2024.10.25 |
|---|---|
| Operator 개발: 컨트롤러 동작방식 이해하기 (0) | 2024.10.14 |
| kind: 다른 네트워크 대역의 클러스터 2개 만들기 (0) | 2024.10.05 |
| 쿠버네티스 Metric Server 설치 및 확인 방법 (0) | 2024.09.24 |