

https://youtu.be/AVEBcZc0YsQ?feature=shared
이 발표에서는 쿠버네티스 환경에서 성능 병목을 제거하고, 최신 커널 기능과 Cilium의 혁신들을 통해 네트워킹 성능을 극한까지 끌어올린 과정을 소개했습니다.
아래는 발표 내용을 토대로 정리한 주요 내용입니다.
https://isovalent.com/blog/post/cilium-netkit-a-new-container-networking-paradigm-for-the-ai-era/
Cilium netkit: The Final Frontier in Container Networking Performance
In this blog post, we're looking at Cilium's support for netkit - a revolutionary Linux kernel networking technology for high performance.
isovalent.com
이 문서에도 같은 내용이 담겨있긴 합니다.
왜 네트워크 성능 최적화가 중요한가?
- 확장성: 클러스터 규모가 커질수록 네트워크 트래픽도 증가
- 지속 가능성: 기존 인프라의 효율성 제고, 온프레미스 비용 절감
- 성능: AI/ML 워크로드로 인한 대량 데이터 처리 수요 대응
쿠버네티스 기본 네트워크 아키텍처의 한계
표준 쿠버네티스 네트워크 경로는 다음과 같습니다

- Pod → veth → upper stack(IP forwarding, netfilter 등) → NIC
주요 병목
- kube-proxy: 많은 사람이 알고있는 서비스가 있을 경우 선형 탐색으로 오버헤드가 크게 발생
- netfilter & upper stack:
- 트래픽이 Pod를 나와서 egress 방향으로 갈 때, 커널에는 skb_orphan()이라는 함수가있음. TCP 트래픽에서 이건 “이 패킷은 이미 노드를 떠났어요”라고 TCP 스택에 알려주는 역할, 실제로는 아직 노드 안에 있죠. 이건 netfilter의 TPROXY 같은 기능들이 의존하고 있어서 쉽게 제거할 수 없었음
- skb_orphan() 호출이 너무 빠르면 인해 TCP 백프레셔가 깨지고, TCP 스택은 “패킷이 나갔다”라고 생각해서 더 밀어넣게 되고요. 그렇게 되면 전송 버퍼 제한을 우회하게 되면서, 결국 성능 저하로 이어짐
- veth의 backlog 큐: softirq 처리를 유발 → 지연시간 증가
성능을 끌어올리기 위한 최적화 여정
1. BPF kube-proxy 제거

- 기존 kube-proxy는 iptables 또는 IPVS를 사용 → 느림
- 해결: eBPF 기반 로드밸런서로 대체 (TC 또는 XDP 레이어에서 직접 처리)
- 효과: 서비스 탐색 비용 제거, CPU 사용량 감소, 요청 지연시간 단축
2. Bandwidth Manager
참고) Better Bandwidth Management with eBPF 이 발표 자료 보면 더 좋을듯!?
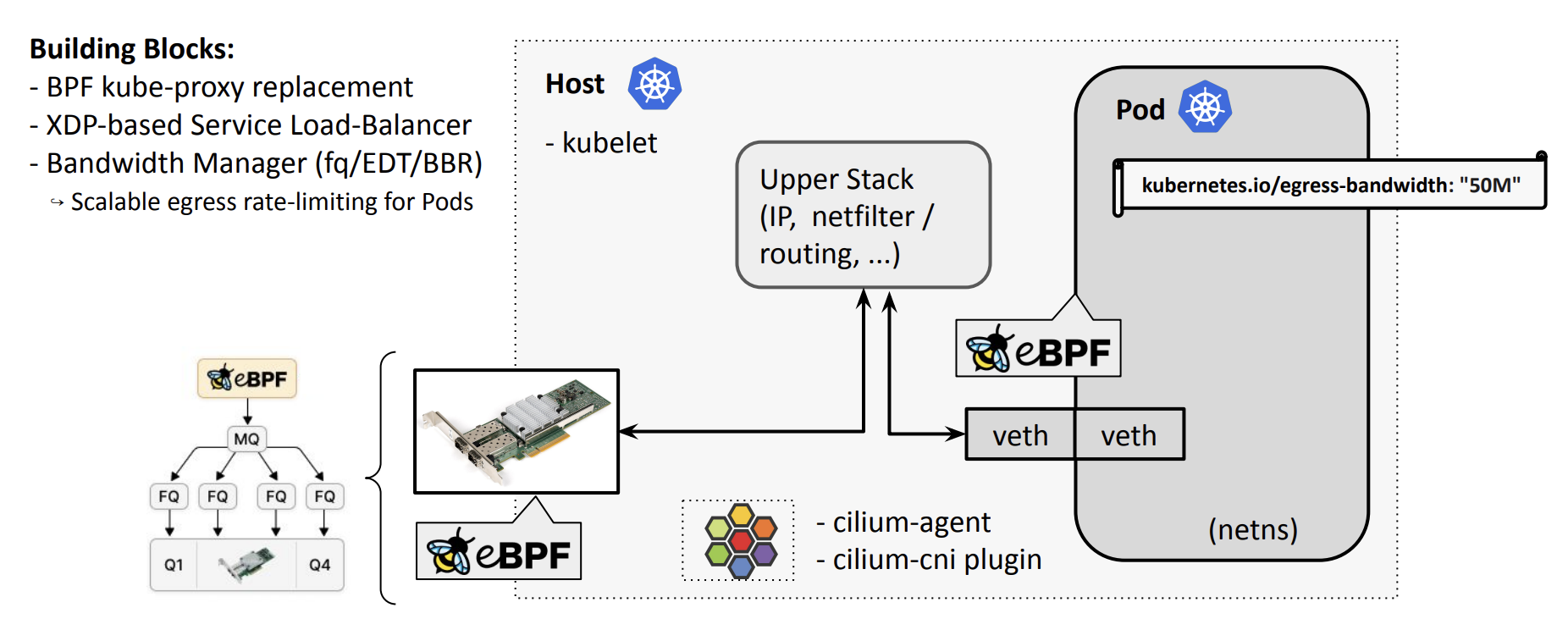
- 구현 방법:
- 리눅스 커널의 fq 스케줄러와 BPF를 통해 패킷 전송 시점(timestamp) 제어
- NIC의 전송 경로(TX path)는 일반적으로 다중 큐(multi-queue)를 갖고 있음. 그래서 fq—Fair Queueing 스케줄러를 커널에서 설정하고, 거기에 “이 패킷은 언제 나가야 해요” 하는 출발 시점(departure time) 을 설정하는 BPF 프로그램을 붙임
- 커널 스케줄러가 이걸 보고, 락(lock) 없이도 정확하게 속도를 조절할 수있게 됨
- 리눅스 커널의 fq 스케줄러와 BPF를 통해 패킷 전송 시점(timestamp) 제어
- 효과:
- 고정된 속도 이상으로 트래픽이 치솟는 것을 방지
- P99 지연시간 최대 4배 감소
- BBR congestion control 사용 가능 → Wi-Fi 환경에서도 부드러운 스트리밍 제공
3. BPF Host Routing

- 기존에는 Pod ↔ Host 간 라우팅이 상위 네트워크 스택을 거쳐야 함 → 라우팅할 때 상위 네트워크 스택을 거치지 말자
- 두 가지 새로운 커널 헬퍼를 도입
- bpf_redirect_peer() – veth의 Ingress 방향에서 빠르게 네임스페이스 전환
- bpf_redirect_neighbor() – Egress 방향에서 이더넷 레벨로 패킷을 인젝션
- 효과:
- 상위 스택을 우회하기 때문에, 아까 이야기했던 skb_orphan() 문제가 사라짐
- TCP 성능: 63Gbps → 90Gbps
- 상위 스택 우회로 CPU 사용량과 지연 모두 감소
TC의 재설계: TCX
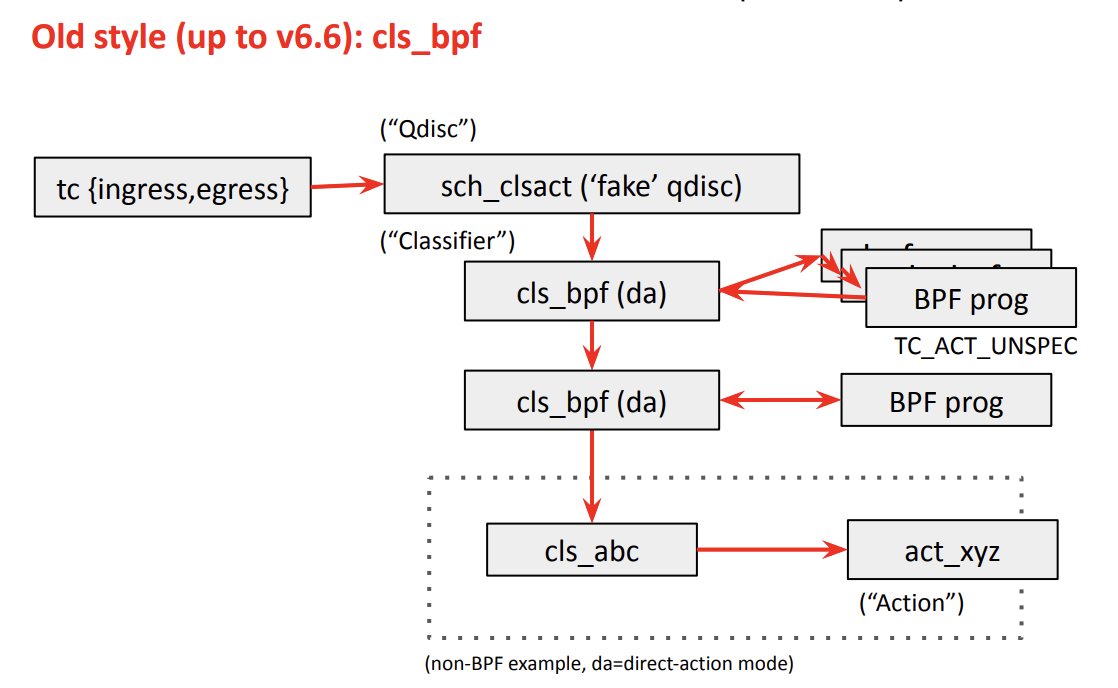
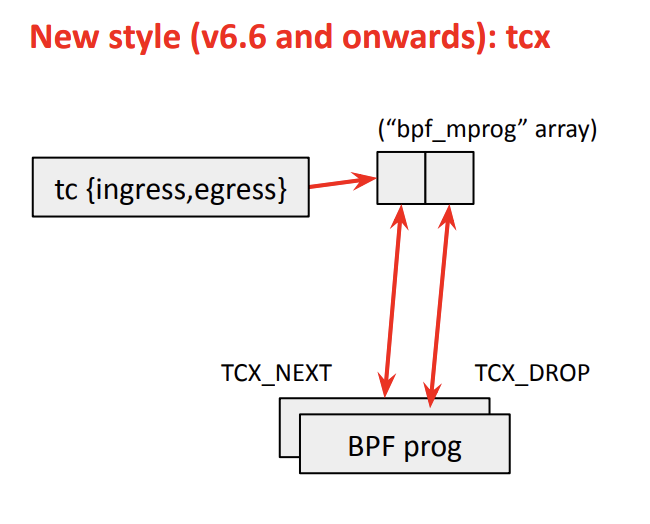
- 기존 TC BPF는 구조가 오래되고 비효율적이었음
- 개선: TCX(Traffic Control Express) 도입
- BPF 진입 포인트를 간소화
- 연결 리스트 대신 배열 기반으로 구현된 bpf_mprog(BPF 멀티 프로그램을 효율적으로 관리하는 구조) 도입
- 효과:
- TC를 동시에 쓸 경우 충돌이 나거나 꼬이는 경우가 있었는데, bpf_link와 같은 새로운 BPF 개념들을 TC에 적용하면서 이 문제도 해결
- 의존성 컨트롤이 가능해짐 - ex) “이 프로그램은 저 프로그램 앞에 붙어야 해” 같은 상대적 위치 제어도 가능해짐
- bpf_mprog 도입으로 캐시 미스가 줄어들고, 더 빨라짐. 캐시 효율 UP
veth의 한계를 넘어서: NetKit

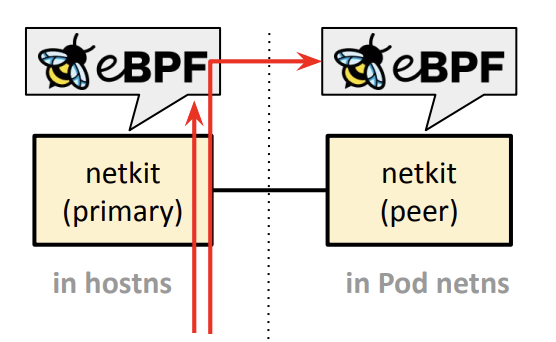
- 문제점: veth를 사용하면 패킷이 Pod에서 나올 때, per-CPU backlog 큐에 들어가 병목 발생
- NetKit은 L3 기반 새로운 인터페이스 도입
- veth의 호스트 측에 붙였던 BPF 프로그램을 Pod 내부 인터페이스에 BPF 직접 로딩 하자 → 정책 우회 방지
- veth는 L2 디바이스이기 때문에, ARP 해석 같은 부가적인 작업하니 L3기반으로 만들자
- NetKit 정리
- 빠른 네임스페이스 전환 지원
- egress 경로에서 바로 전송
- FIB lookup과 결합 가능
- 효과
- 트래픽이 softirq 없이 user thread context에서 바로 처리됨
- 지연시간, 처리량 모두 호스트와 동일 수준 달성
대규모 데이터 워크로드를 위한 준비: Big TCP
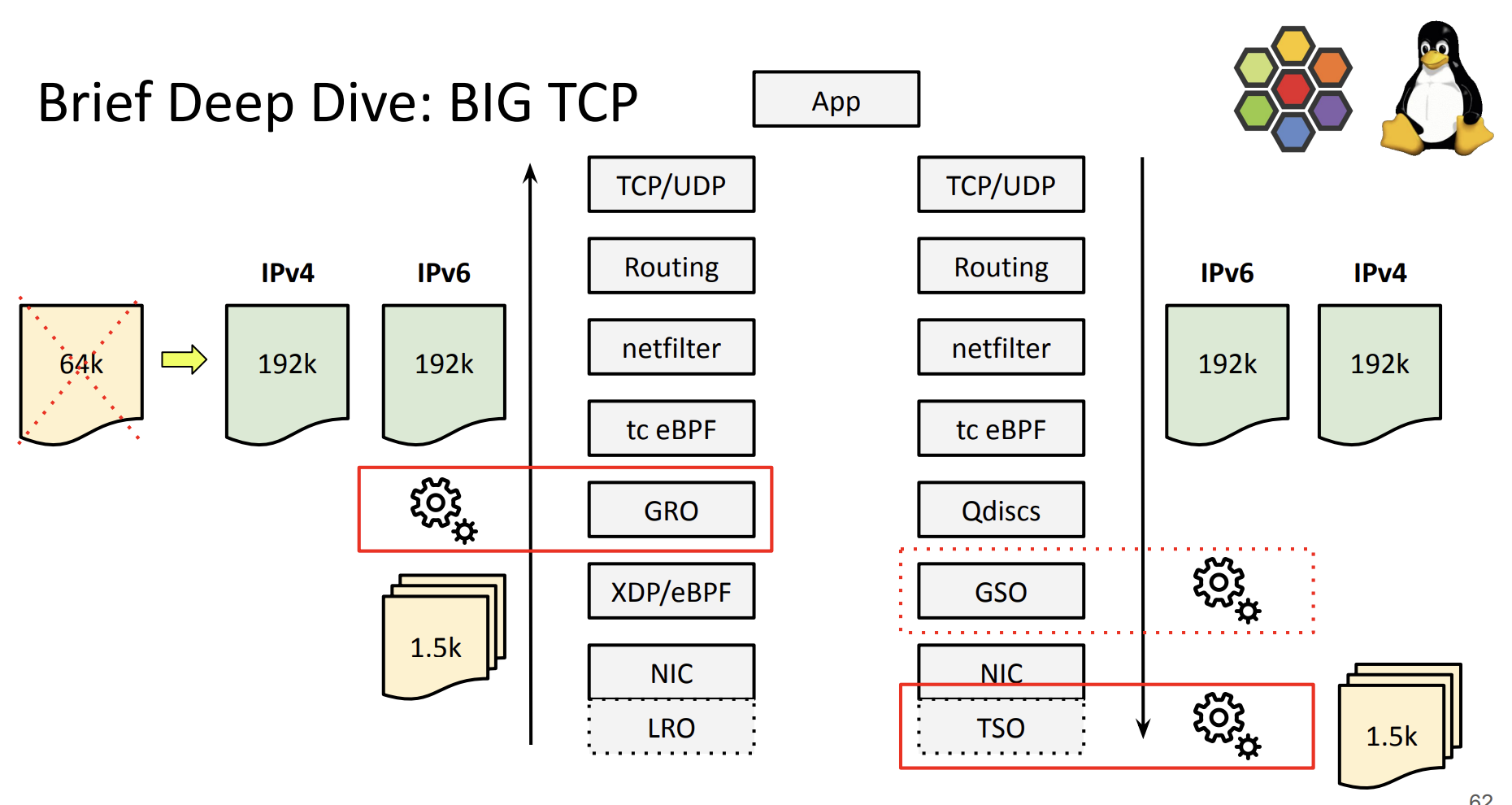
- 구글의 TCP 커널 메인테이너들이 만든 기술, 이 기술의 목적 → 고속 NIC(200G, 400G 이상)를 제대로 활용위해 패킷을 더 크게 묶자
- Big TCP는 IPv6의 hop-by-hop 옵션에 Jumbo Frame 헤더를 넣어 32비트 길이 값을 사용
- TCP 패킷들을 최대 192KB로 묶어서 처리 - 테스트 결과 192K가 가장 sweet spot
- NIC에서 하드웨어 TSO/GRO로 자동 분할, NIC마다 지원되는 크기가 다르지만 자동으로 설정 됨
- 효과:
- P99 지연시간 2배 감소
- 트랜잭션 처리량(TPS) 비약적 증가
- 커널이나 앱 코드 수정 없이 Cilium 설정만으로 활성화 가능
향후 예정된 기술들
- TCP 마이크로초 타임스탬프: RTT 추적 정밀도 향상
- BBR v3: 재전송율 개선, 더 나은 혼잡 제어
- TCP Zero-Copy: GPU 직접 메모리 매핑을 위한 기반 마련 중
- header/data 분리 지원
- Big TCP + zero-copy 조합 → 극한 성능 가능
'K8S > cilium' 카테고리의 다른 글
| containerlab을 사용하여 cilium + BGP 테스트 환경 만들기 (6) | 2025.08.15 |
|---|---|
| [발표영상정리] Better Bandwidth Management with eBPF (2) | 2025.08.03 |
| cilium 1.18.0 달라진점 정리 (3) | 2025.08.02 |
| gce에 cilium native-routing으로 설치하기 (0) | 2025.02.02 |
| 네트워크 패킷 추적 도구 - PWRU: Packet, Where Are You? (1) | 2024.10.21 |